-
Diabetes Prediction based on diagnostic measures
This project was a task proposed on a kaggle dataset.
The objective was to diagnosticly predict whether a patient has diabetes or not based on the certain diagnostic measurements.
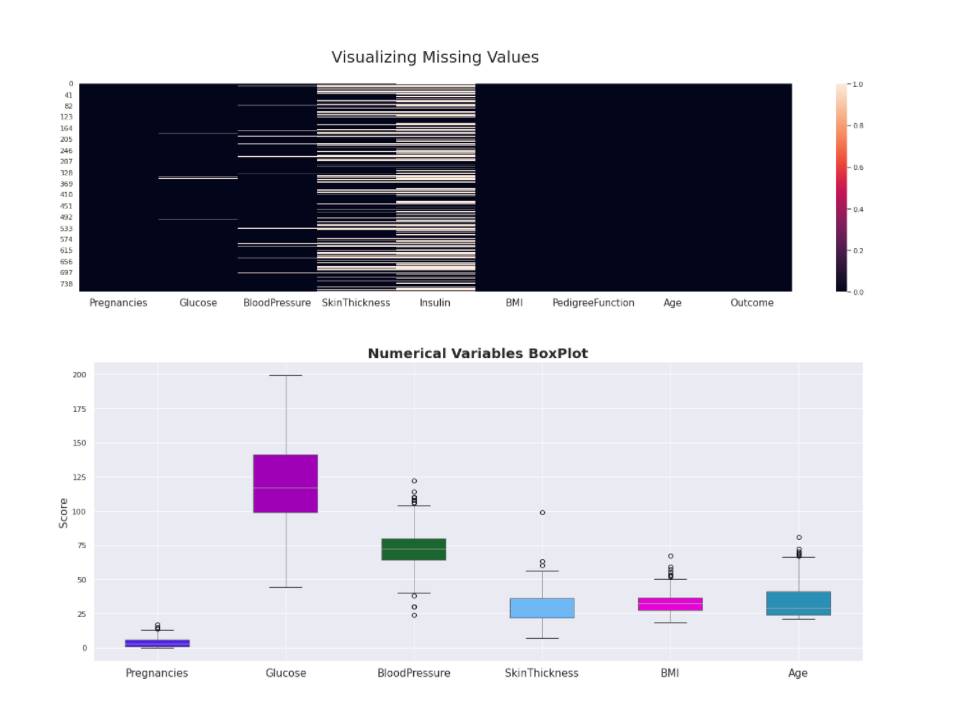
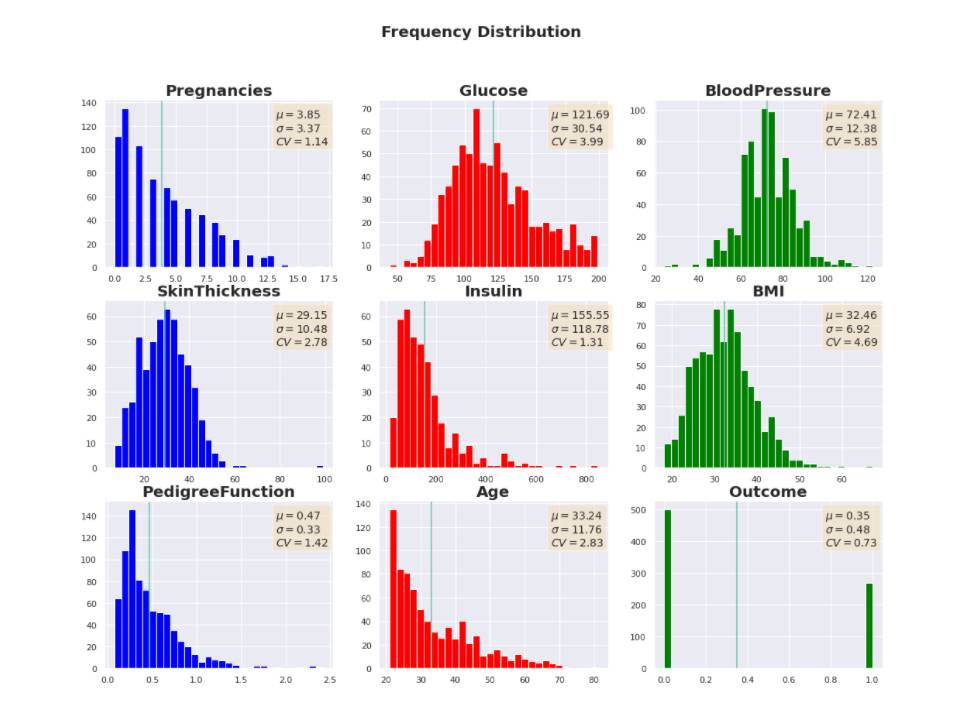
The data was checked, explored and then prepared for modelling. Given the high percentage (~50%) of missing values for one feature, machine learning based imputation was applied.
The Support Vector Machine model was applied, but the accuracy of multiple models was assessed.
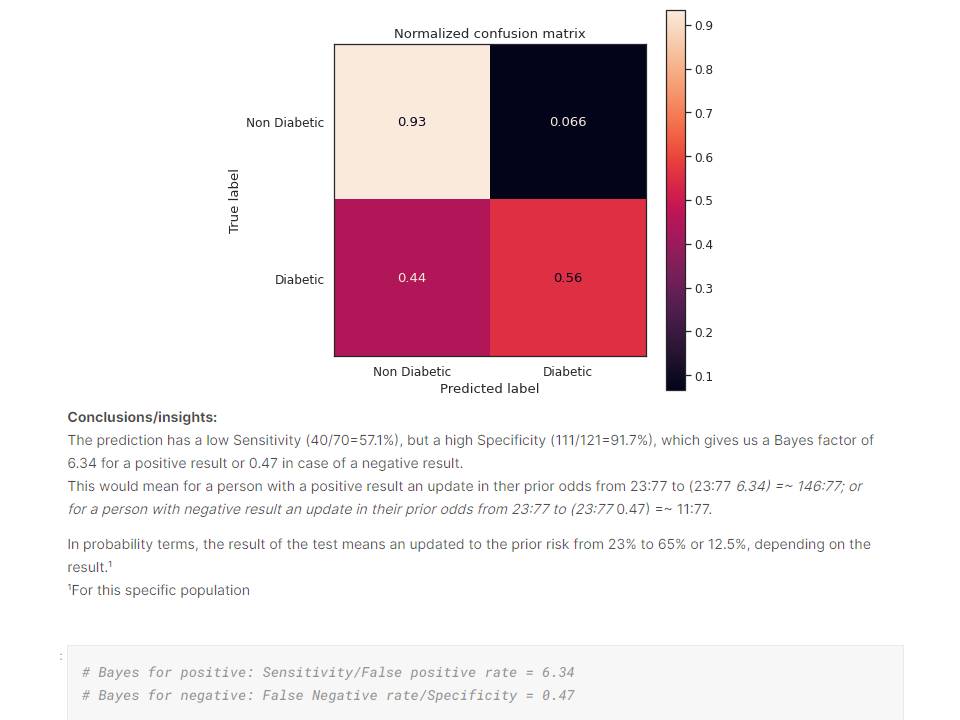
The final model had an accuracy of approximately 80%, with low sensitivity (57.1%), but high specificity (91.7%).
In practical term, the model can updated the prior risk for an individual from 23% to 65% or 12.5%, with a positive or negative result, respectively.
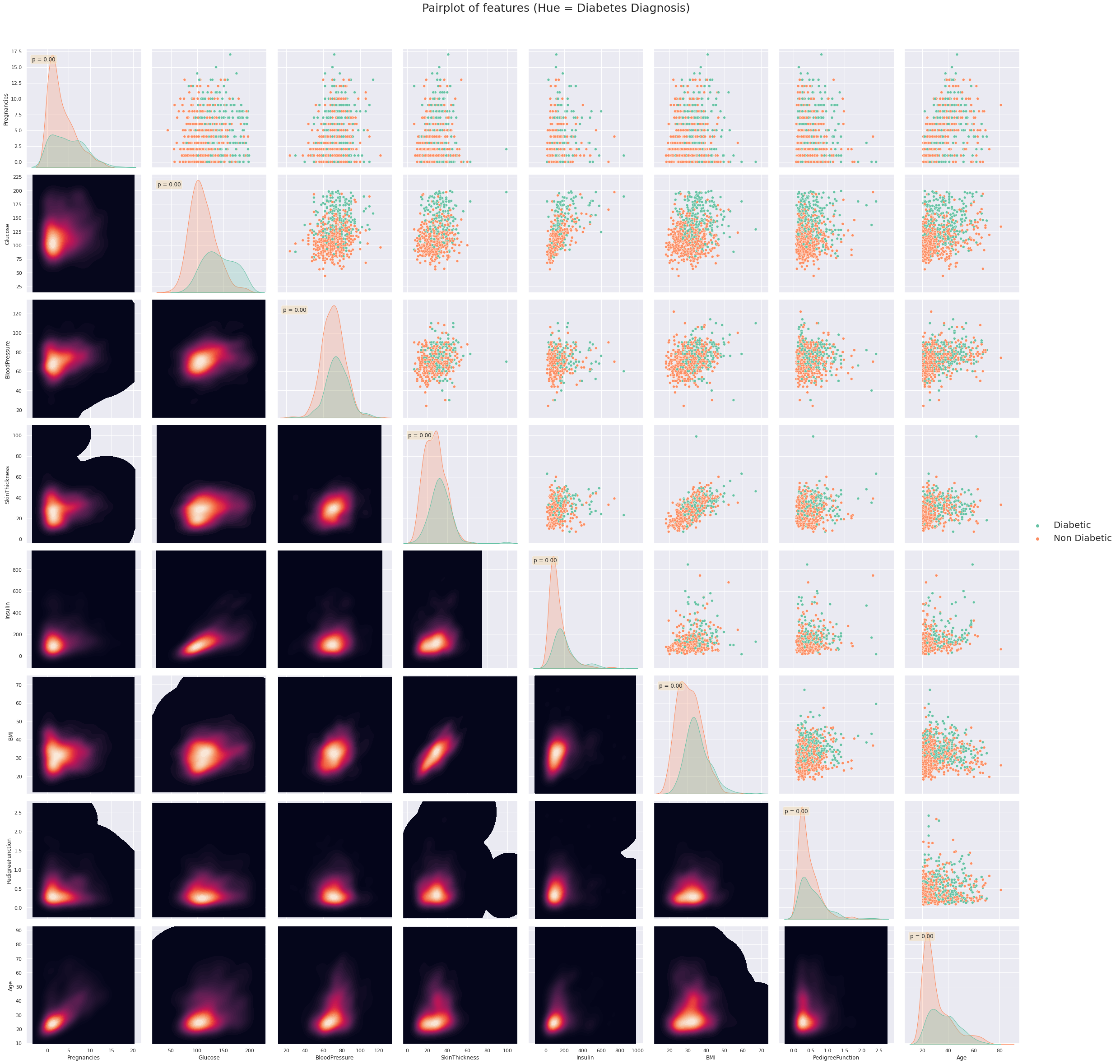
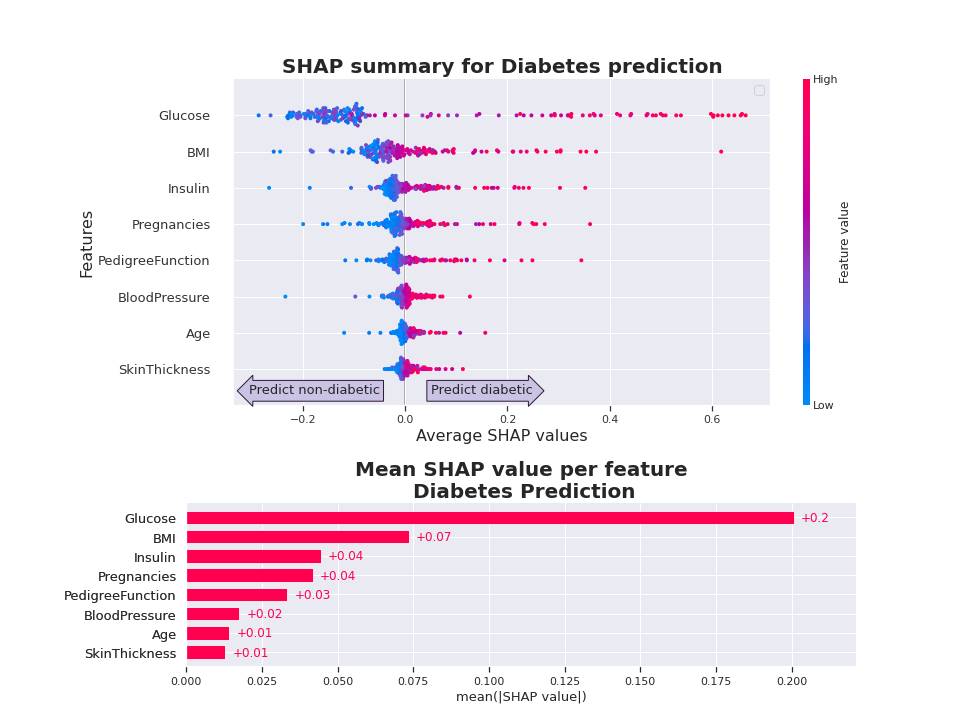
Afterwards, two methods were used to assess the most important features, namely Shapley Values and Permutation Importance. Both indicated Blood Glucose, Insulin and BMI as the most relevant features.
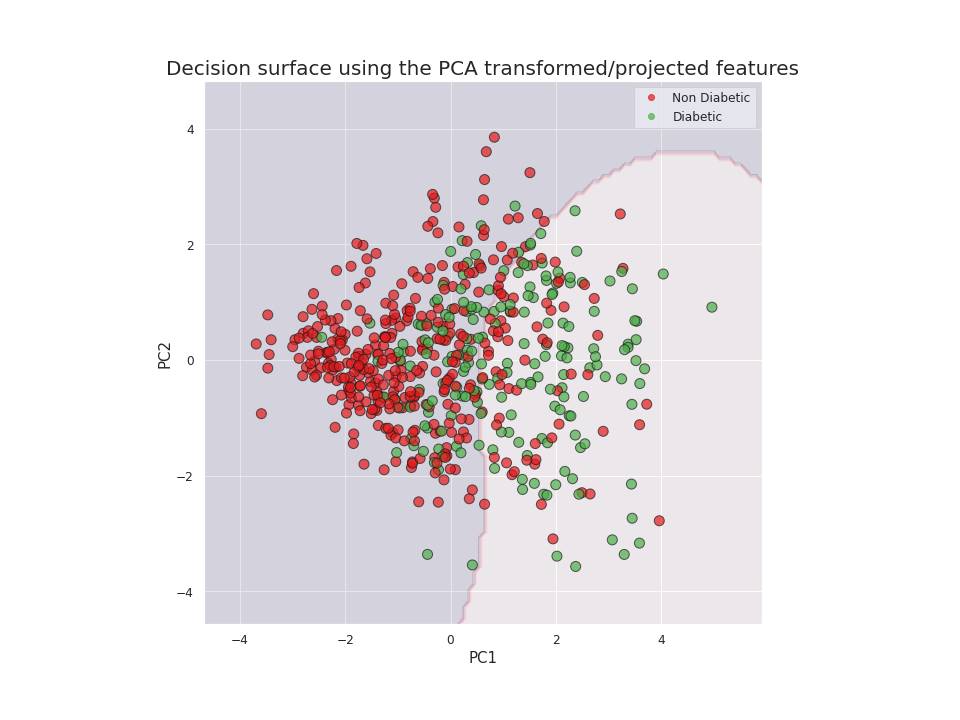
At the end, a decision surface of the model was presented in 2D using PCA transformed features, as a visualization alternative.

Related Images